关键词 大数据 编码 基因组 核酸 转录 药物 蛋白 细胞 序列 人类基因组 核酸疫苗 人工智能 遗传密码 新冠病毒 基础研究 神经网络 深度学习
2023年1月4日,广州实验室苗智超研究员邀请了中国科学院生物物理所的陈润生院士进行了线上学术报告“大数据、人工智能和核酸药物”, 是Guangzhou RNA Club 2023年的第一场学术报告。陈润生院士是最早从事生物学和生物信息学研究的科研人员,20多年来一直专注于生物信息学的研究,是中国早期参与人类基因组测序与拼装工作的人员之一,主持了国内生物信息学的一些早期的工作,开创性的工作。近十几年来主要从事非编码RNA 的系统发现与功能研究,发表学术论文有180多篇。陈院士是我们RNA领域的大专家。
大家知道,实际上RNA它的所有的发展都是来自大数据。换句话说,我们当前的生物医学的发展实际上都依赖于 90 年代初开展的以破译人的一串密码为代表的基因组研究。从此整个的大数据就进入了生物医学领域,带动了越来越多的深刻的变化。当然我们知道现在组学大数据跟医学的结合,就导致了整个医学的精准医学的出现。所以大数据是在促进整个社会医学变革的,一个原始的动力。
什么是大数据?
陈院士将数据比做一串密码,人的一串遗传密码有 4*3* 10^9,如果以A4纸显示每个人的遗传密码,那就可以形成一百万页。大数据本身庞大的数据量和背后隐藏的深刻的生物学含义迎来了生物医学的变革。图1展示的仅仅只是一段。

图1. 部分人类遗传基因信息
陈院士在报告中也为我们介绍了他参与的人类基因组的相关研究。中国开展人类基因组研究应当是从 1992 年开始的,所以在 90 年代,实际上陈院士已经参与了大数据的破译的研究,逐渐地跟国际在领域融合了。除此外,因为人类基因组中国只承担了1%的部分,当时中国科学家就考虑我们应当独立地来完成一个复杂体系的基因组研究。随后我们国家就独立地完成的水稻基因组的研究,这是一个很大的工程。当时 science这一期的主编是鲁宾斯坦,他专门对中国科学家表示祝贺,同时把 science 这期水稻基因组封面的挑选权交给了中国科学家。所以我们现在很高兴地看到,这期的science 水稻基因组的区封面是我们云南红河哈尼族自治州的一个水稻梯田。它将永远地记录到科学史上,这是我们的中国科学家的光荣。

图2. 中国科学家主导水稻基因组工作当期science封面
大数据带来的重要影响是什么?
陈院士首先展示的是复杂的真核细胞的基因组和简单的2019-nCov的基因组(图2)。如果没有大数据,我们将对整个基因组是一无了解。图3展示一个简单的早期新冠病毒的基因组,它只有 29903 个碱基。我们几天之内就可以完整地破译所有的新冠的序列以及所有的突变。以及它对整个人类健康带来的影响,然而,在100年前,我们并不能如此迅速获得基因组信息。例如,1919年国际流行西班牙流感,当时至少估计有 2500 万人罹难。直到 1933 年(拖了15年),才找到了这个病因是流感病毒;而直到 2005 年,它的完整序列才被测出。可以看到由于当时没有组学大数据,所以导致的后果是极端严重的。
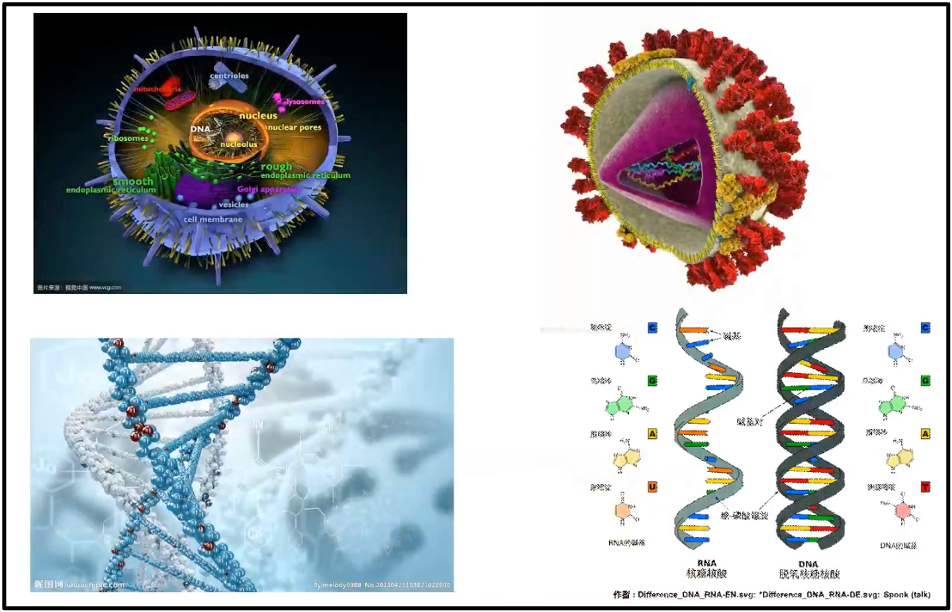
图3. 复杂的真核细胞的基因组和简单的2019-nCov的基因组
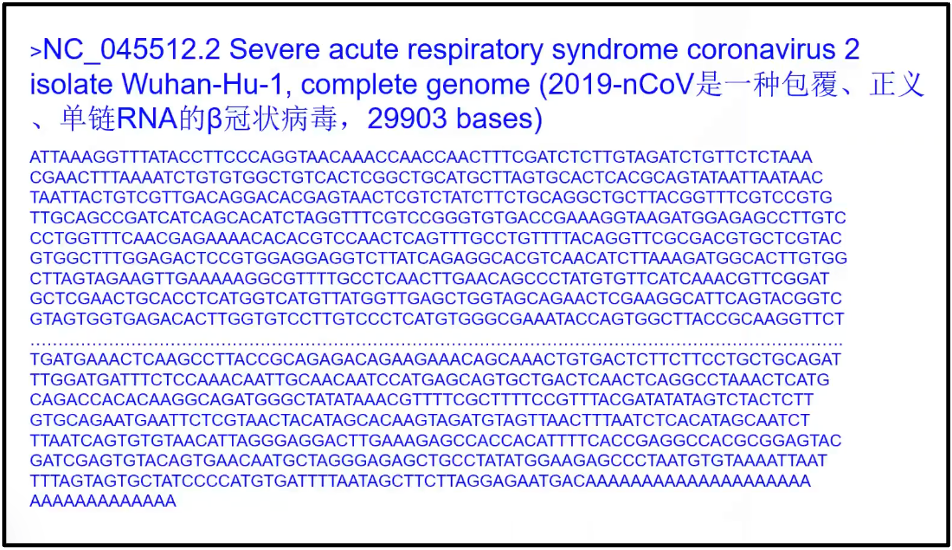
图4. 一个简单的早期新冠病毒的基因组
陈院士讲述,相比于100年前,我们积累的知识和迅速发展的组学技术使得我们有了很多主动权,所以大数据对未来的影响实际上是巨大的、是深刻的。Standford 的 Snyder 教授,他通过不断地测自己的血液大数据来预测他自己的健康状况和他健康的未来的发展,预测出他可能存在代谢疾病的危险状况。通过大数据能够非常吻合的预测到它将来可能的整体的变化,这是没有大数据所根本不能实现的(图5)(Snyder 2014)。 2020 年8月13 号的新英格兰医学杂志,对美国所有非小细胞肺癌的大数据做了深刻地挖掘,非小细胞肺癌大约占肺癌总量的 80%- 85%,所以它基本上可以代表着肺癌的变化的情况(Chen et al. 2012)。研究发现,美国从 2001 年开始,肺癌的发生率是逐年降低的(蓝线);而死亡率(红线)也是逐年下降的。即美国的非小细胞肺癌似乎是可防可治的。陈院士在报告中,分析了主要原因,因为对大数据的深刻的挖掘,找到了非常多的跟肺癌发生相关的靶点,比如ROS1、BRAF等,目前国内主要靶点是EGFR及ALK。
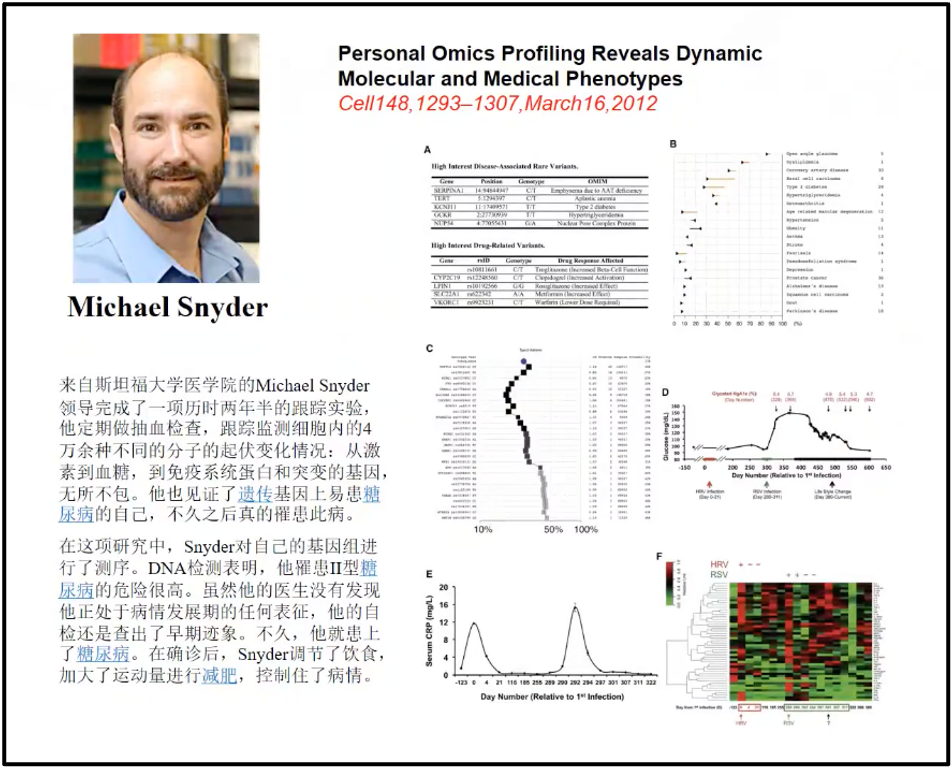
图5. Snyder 教授利用血液大数据来预测自身的健康状况和未来的发展
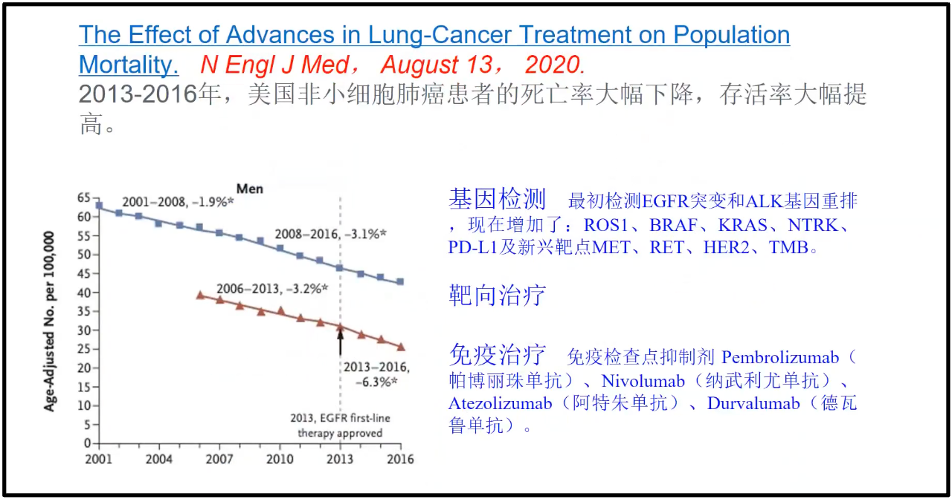
图6. 2013-2016年,美国非小细胞肺癌患者的发病率和死亡率统计分析
这些例子都说明大数据带来的深刻的影响和根本意义,但是大数据发展过程当中,陈院士讲述了我们还有很多的问题没有解决。其中最大一个问题就是基因组中的破解的问题。我们知道如何对人的遗传密码进行测量,这是非常简单的,因为我们有非常好的一代、二代、三代的测序技术,所以目前的测序成本非常非常低了,即每个人都可以测量自己的遗传密码。但问题是我们现在即便知道了自己的遗传密码,我们如何去解析呢?
基因组的“暗物质”--lncRNA
现在我们知道在人类基因组中,真正遵从中心法则,编码所谓蛋白质和多肽的序列,充其量不会超过3%。而另外 97% 的遗传密码并不用来编码所谓的蛋白和多肽这些序列的。刚开始大家称这97%为 junk ,就是所谓的垃圾。后来大家意识到这些 junk 实际应当是非常值得研究的问题。从1993 年开始,陈院士所带领的课题组就集中到研究人类基因组当中的非编码序列。在2010年SCIENCE 评选当年的科学的十大突破,第一个指出来的就是 genome stock matter,就是基因组当中的暗物质。提到人类基因组中大概只有 1. 5% 的基因组序列执行编码功能。现在看来可能要比 要多于1.5%,但是充其量也不会超过3%。
最初lncRNA相关研究进展比较缓慢。主要存在两个因素:一个因素是支撑这些非编码序列功能的研究结果太少,数据太少,实验也太少。第二个因素,我们当时没有有效的测量工具与方法来找到来自非编码序列的转录本。所以从 1993 年开始,我们就从理论研究着手,到 2000 年的时候,我的实验室建立了湿实验的体系,即开始自己发现新的来自非编码序列的转录本,随后研究它的功能。

图7. 基因组中的暗物质
一个活细胞中基本元件不仅有蛋白,还有核酸,生物机器这个网络实际上远比我们想象中复杂。 RNA 的参与是生命功能复杂化当中的一个非常基础和关键的步骤。2014年,陈院士和赫捷院士的合作研究发现在有些食管癌的病人中(图7),蛋白多肽标志物基本都没有变化,但非编码的转录本,是有明显变化。所以他们就提出来其实部分病人,它的癌症标志物并不是蛋白,而是那些 RNA 的转录本(Li et al. 2014)。同时研究提出影响食管癌病人存活率的3个 lncRNA ,同时也作为疾病诊断分子申请了专利。

图8. 非编码RNA 图谱研究解释影响食管癌病人存活率的重要标志物
此外,陈院士也在肿瘤干细胞与lncRNA之间的关系(图9),例如肿瘤干细胞干性细胞的维持,研究发现,除了我们现在知道的很多蛋白之外,其实有很多 RNA 的因子也参与了整个肿瘤干细胞的调控。例如 link-TCF7,它就是影响肿瘤干细胞的干性的维持(Wang et al. 2015)。
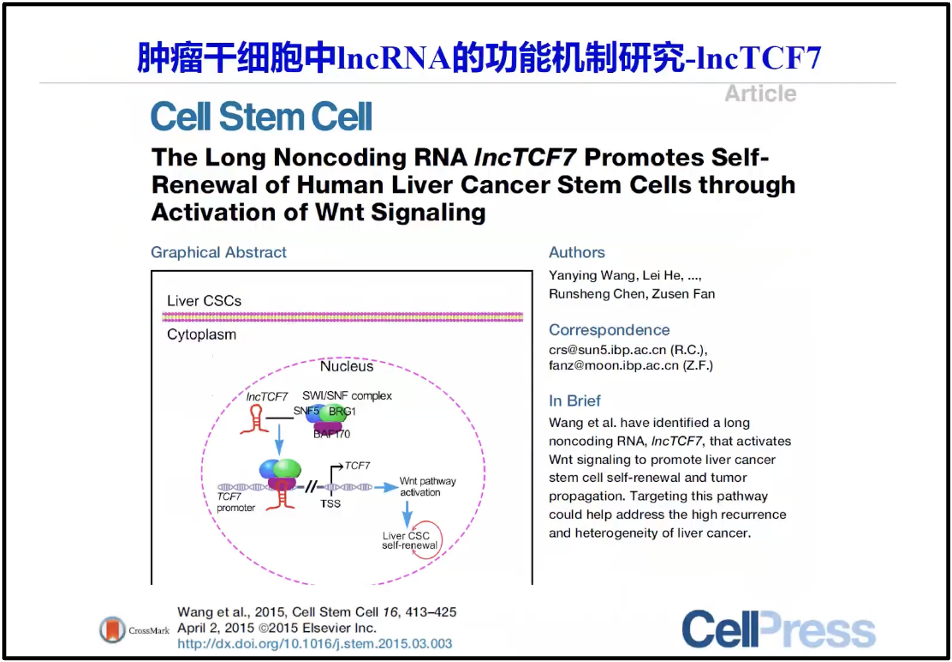
图9. 肿瘤干细胞与lncRNA之间的关系
众所周知,PD1、 PDL1 参与调节肿瘤微环境。实际上陈院士所领导的课题组的研究发现,维系肿瘤微环境或者影响肿瘤微环境的,不仅仅只是像PD1、 PDL1这些蛋白和多肽。实际上大量来自非编码的转录本RNA在维系肿瘤维环境当中起着非常重要的作用。陈院士发现 IncKdm2b(图10),可以调控淋巴细胞的微环境(Liu et al. 2017)。
所以研究 RNA 的功能和作用解析的 97% 的功能将是一个非常重要、非常基本和非常带有根本性的这样的工作。
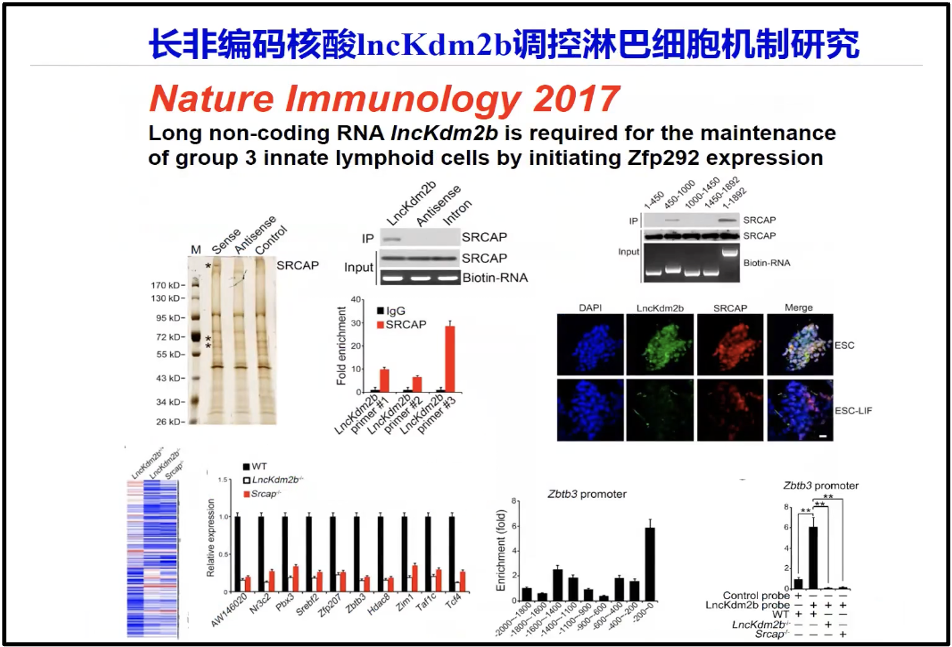
图10. IncKdm2b 调控淋巴细胞机制研究
大数据分析---重要挑战
陈院士在汇报中阐述到,现在整个时代的变件变化是由转录组、蛋白组、代谢组、表观组这些组学大数据的冲击而引起的。由于它的带动,我们知道很多数据可以成为大数据(图11)的来源,比如电子病例,它把每一个人的病例都以电子病例的形式保留下来了,那它就是一个以自然语言来描述重要的生理生化指标;影像学的数据,疾病演变过程当中的动态数据,肠道菌群、皮肤菌群数据等;大气的污染程度,水温、地质当中的化肥、农药本体辐射等,所有这些东西都可以数值化形成大数据。实际上,如果我们抽象地看这些大数据的数学物理特征,会发现它是极端复杂的。仅从复杂性来讲,它又是多尺度,高维度的。所以如何能够把这些不同的数据能整合在一起,这是极端复杂的问题。从时空来讲,它是动态的,因为生命是鲜活的,它不像简单的物理化学系统,它实际上是非线性,有向的。过去我们认这个体系是由单一节点组成的,现在看来这个节点的属性也是高度复杂。

图11. 生物医学大数据的基本分类
如何用建模的方法来解决,是当前组学大数据或者整个生物医学大数据解析所面临的困难。我们知道,如何将如此复杂的情况进行简单建模,现在依然是困难的。当然,不排斥你局部的逐渐的降维、简化这些模型,但是如何全局地考虑这些因素,这是一个复杂的数学问题,然而,这些问题的产生也推动了人工智能这些技术的发展。
精准的“三个关键”
陈院士认为要解决这个问题,一方面我们要增加分子水平的组学数据;另外一方面,我们要把所有的生物学的特征,所有疾病的表形,进行表征化与定量化。目前国内已经有研究团队正在牵头来建立表型组的数据库。所以当我们一方面有了分子组学,一方面有了表型组学的时候,我们现在很容易借助控制论、信息论里面形成一个成熟的哲学逻辑----黑箱理论(图12)。即我们可以通过信息论、控制论的传递函数理论来构建解析复杂系统的模型。形成从分子组学数据到生物功能和疾病定量化的表型组学数据的映射,逐渐地,黑箱会变成一个灰箱,再从灰箱变成白箱,形成黑箱理论结构。实际上,我们可以构造的各种各样的神经网络,一端是输入端,一端是输出端,中间用一个所谓 AI 的这样的网络来进行描述。如果我们把 training 把这个网络之间搞清楚,那我们网络所带来的生物学机制也就逐渐从黑箱变成白箱。
实际上,这样的技术是当前解决复杂大数据当中的最好的一种逻辑。所以这就是为什么当前 AI 技术能够如此全面、如此广泛地用到所谓生物医学大数据的解析当中。无论是从逻辑上来讲,或从方法论上来讲,它都能给大数据解析带来一个可用的模式。而如果我们纯粹地从数学物理建模来讲,对复杂体系的刻画实际上是相当困难。
因此,陈院士认为 AI 技术会在一段时间内成为我们很好的大数据解析的工具。相较于实验数据来说,AI技术在生物学领域的主要优势体现在两个方面:一是结构预测,AlphaFold2 这些人工智能技术可以很好地预测蛋白质的结构,预测精度达到了实验的90%以上,换句话说,是可用的。这是我自己以前做生物大分子计算没有想到的,所以用这样的技术能够预测天然蛋白值的85%,同时为核酸预测提供了很好的模式,为核酸疫苗、核酸药物的设计开拓了很好的前景。二是影像学方面,目前用人工智能构建的影像系统超过了任何一个独立的医生的准确度,比如 DeepMind 通过处理数以千计的视网膜扫描图像,训练出了一种人工智能算法,可以比人类医生更加高效、准确地检查出眼底疾病。这展示了人工智能对生物大数据处理的精度和作用。这个作用会向大数据的其他方面延展,而为生物医药提供更好的工具。当然,我们相信随着对人工智能技术的发展,训练数据的不断地整合,以及AI技术的不断地提高(图13),人工智能可以帮助我们分析更复杂的基因组数据(Alipanahi et al. 2015)。
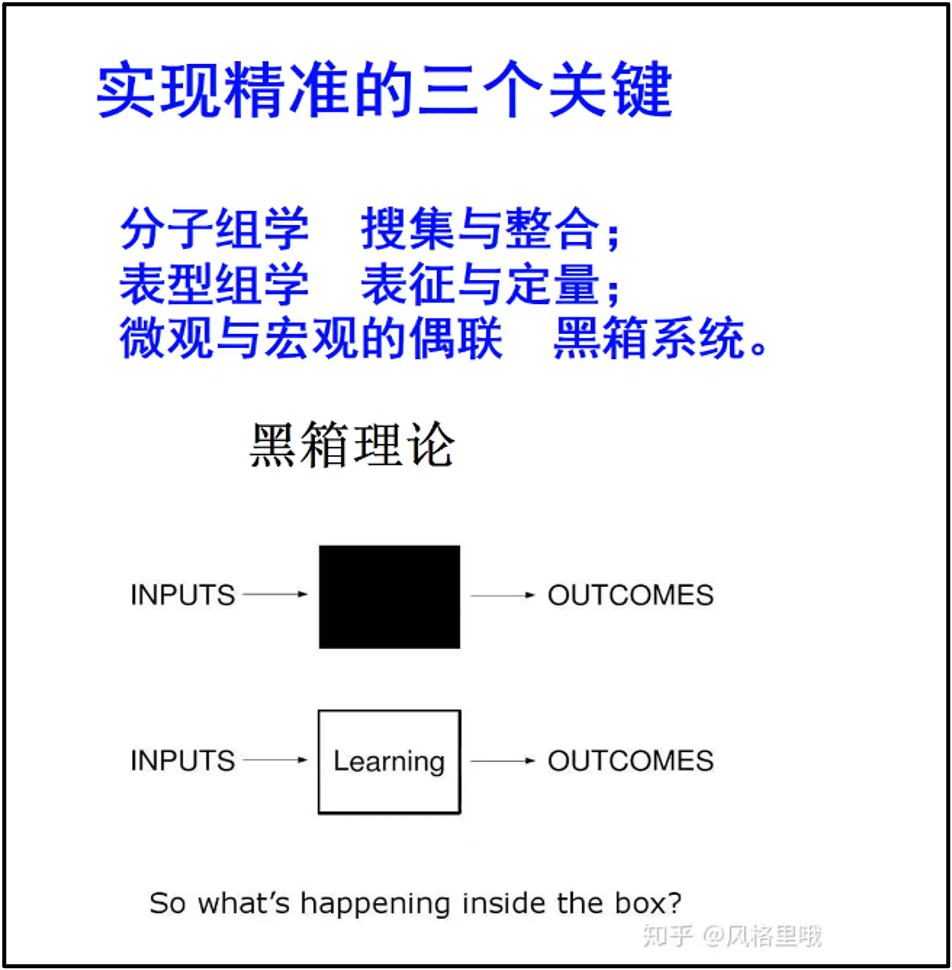
图12. 实现精准的三个关键和黑箱理论
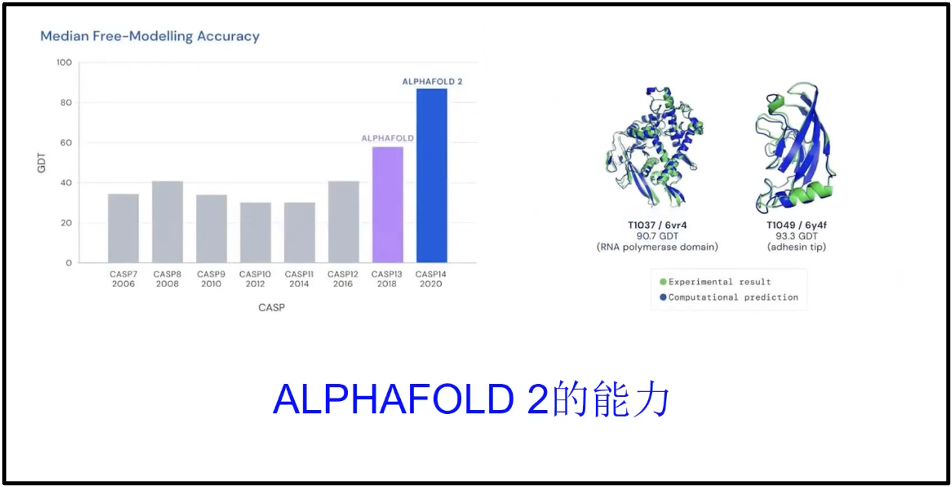
图13. Alphafold2 与蛋白质结构预测
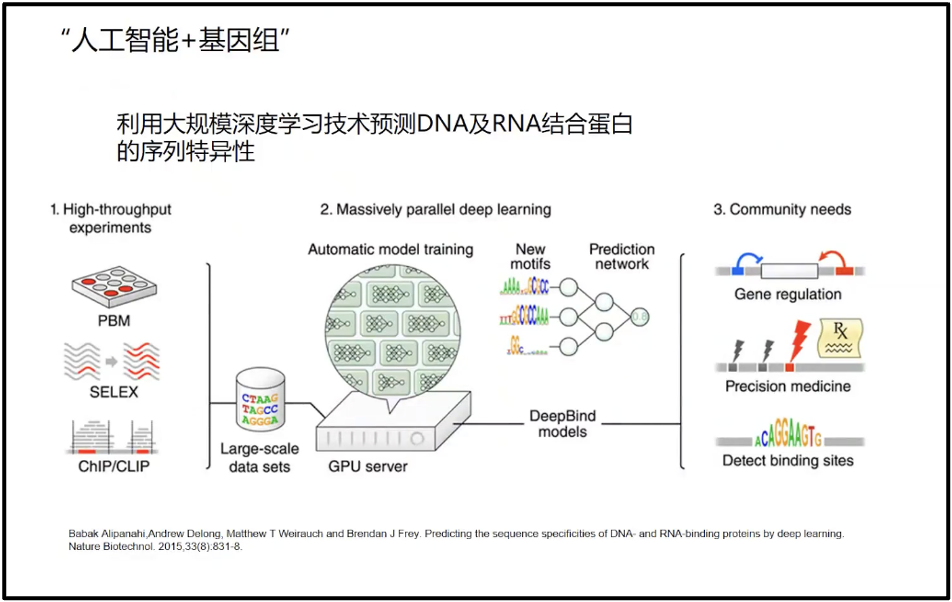
图14. AI 与基因组
数据的收集与标准化非常重要
陈院士的学术报告中,认为现在整个的人工智能,依赖于三个方面的发展,一个是模型,一个是数据,一个是算力。模型是专业人员在研究的,算力是整个各个地区的计算能力,这两项在我们国内是有的。超级计算机也在不断地发展各种各样的模型。但是数据本身是掌握在用户手里的,所以任何从事大数据研究的基本理念就是你能够建立一个足够丰富的,信噪比足够好的数据,这是你用 AI 技术来获得更多知识的一个基本要素,这是非常重要的。所以数据是获取丰富信息的基本要素,也是我们各个实验室所需要用的 AI 技术当中的非常值得重视的一个环节。我们大脑中的神经网络远比现在使用的神经网络要复杂。所以如何逐渐逼近真实的网络结构,是体系模型构建当中的一个非常重要的因素。
核酸疫苗与核酸药物
新冠疫情大大促进了核酸疫苗跟核酸药物的发展。左侧(图15)是新冠病毒的一个简单的模型,红色的部分实际上就是新冠病毒表面的刺突蛋白(S蛋白),该蛋白可以指导病毒进入人物机体。目前不管是新冠病毒的防治还是疫苗的研发,基本上都是围绕着冠状病毒的 S 蛋白(右侧图蓝色的这些标志物),其可以和受体的ACE2(右侧图里红色的部分)相结合而引起了一系列的过程。
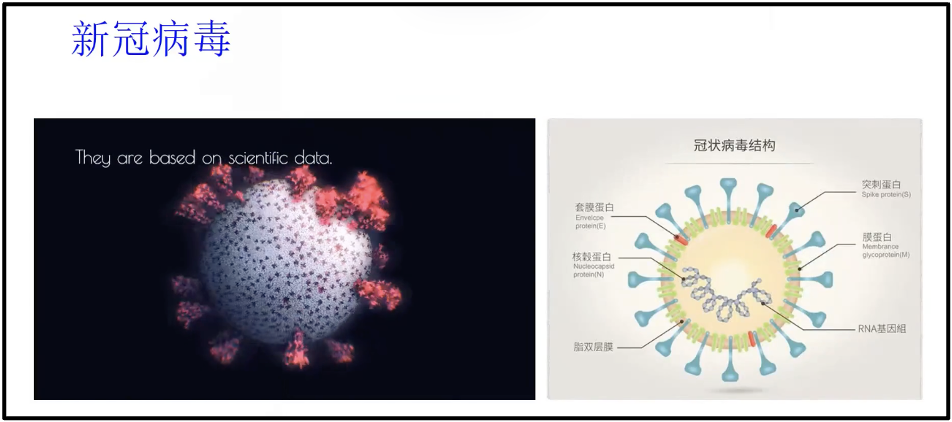
图15. 冠状病毒结构图
当我们有了合适的疫苗以后,就会产生足够的抗体来消除病毒。在这次新冠当中,我们第一次研发出了所谓核酸疫苗,就是mRNA疫苗。其实这个想法非常简单,我们过去的疫苗都是用灭活重组疫苗,就是把病毒杀死以后,或是取病毒的某一些关键蛋白,打入机体诱发机体产生相应的抗体。一个很简单的想法是,与其打入蛋白进去,不如把模板打进去。这就是简单的所谓的核酸疫苗的想法。这个想法已经存在多年了,但是为什么只有这一次疫情期间才真正的产生了核酸疫苗,主要不是 mRNA的设计的问题,当然 mRNA 设计本身也有不断的问题,但非常重要的问题就是如何把 RNA的模板 递送到机体里面去,也就是递送系统成为制约核酸疫苗真正使用的一个关键。
最近十几年,学术界已经对递送系统的研究,使得对核酸的递送达到了可使用的目的。所以这一次真正的核酸疫苗在真正对抗新冠起了很大作用。目前核酸疫苗主要的是两家公司,一个moderna,一个是辉瑞。BioNTech 跟辉瑞联合的生产的这个疫苗,是一个典型的疫苗模型,很多人看过,实际上我们本来大家可以看到中间包裹的绿色的部分,就是所谓的信使RNA。这些 RNA 就是模仿了病毒的 s 蛋白或者 s 蛋白的一个关键区域。它直接注射到机体,但很快会被RNA酶所降解。因此引发了对复杂的递送系统的研究。
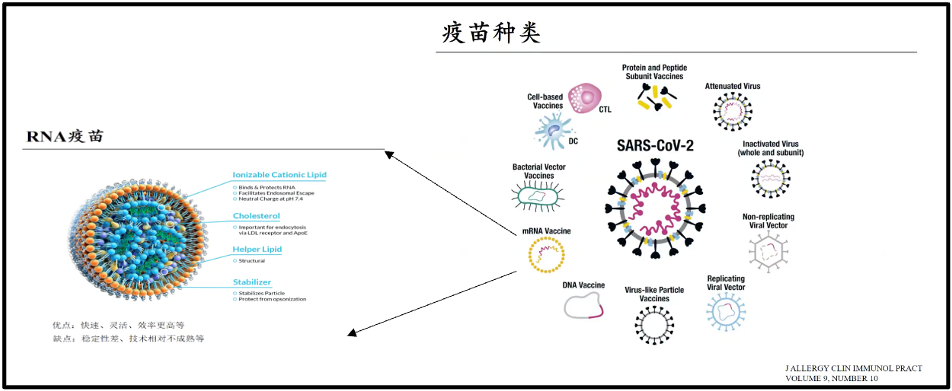
图16. 疫苗种类和RNA疫苗
递送系统
现在成功的递送系统主要借助于纳米颗粒。比方,蓝色的纳米颗粒紧紧地包裹着这些绿色的RNA,而橙色的脂质纳米颗粒则是作为整个总体疫苗的外包装(图17)。即把信使 RNA包裹起来,使得它能够递送到细胞基质里面去。陈院士所领导的课题组也做了一些 RNA 的疫苗的研究,发现RNA 疫苗和传统的灭活疫苗、蛋白疫苗相比,综合抗体产生的能力,通用性,长效性都是优于传统疫苗的灭活疫苗。所以陈院士认为 RNA 疫苗未来在人们对抗这类病毒或者这些烈性传染病当中,一定会为我们带来很大的收益。当然,也带来了巨大经济效益。比如辉瑞公司在 2021 年的财政年报里公布,仅仅是 2021 年的RNA 疫苗的销售额到 367. 8 亿美金,约合 2340 亿人民币。这是一个巨大的数字,说明合理利用疫苗会形成一个巨大的产业。与此同时,RNA药物在 2018 年的 8 月份也真正在人类的药物仿真史上出现了,也就是FDA 批准了RNA 药物了(图15)。
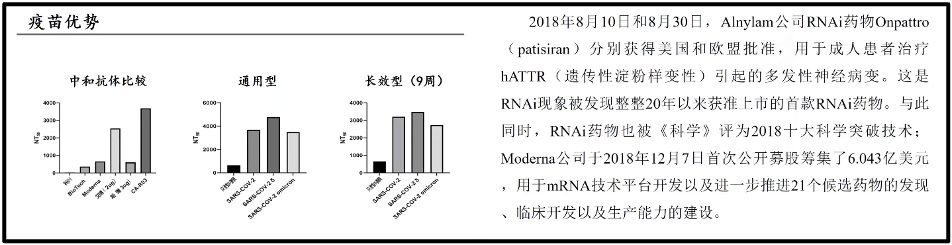
图17. 疫苗的优势和RNA药物
因此,人们认为,如果把小分子的药物作为第一代药物,抗体,细胞作为第二代药物,那么核酸药物就是第三代药物。RNA 药物的优势非常清楚。一个RNA 本身就是一维的线性序列,非常容易设计,而且也非常容易合成,因此它的性价比高。此外,RNA是安全的,因为我们的活细胞里有大量的RNA,所以机体有一个对 RNA 新陈代谢非常重要的一个体系。所以外源性的 RNA很难整合到基因组中。所以RNA既是安全的,又是简单的、快速的、低廉的。这些就决定了RNA 药物必然在很快地会占领药物的舞台(图18)。
陈院士在汇报中举例道,2020 年的欧洲的心脏病学会上, Arrowhead的公司(图)提出了一个降脂药。这个降脂药的本质是一个小RNA 药物。它的降脂效果实际上是跟他汀类药物是可比拟的。但是它打一针可以管半年。现在高血脂病人每天都要吃降脂药他汀类药物,而如果改换成RNA药物,他只要半年打一针就够了。这对病人来说是极端友好的,一年打两针,实际上不用改变他任何状态(图19)。
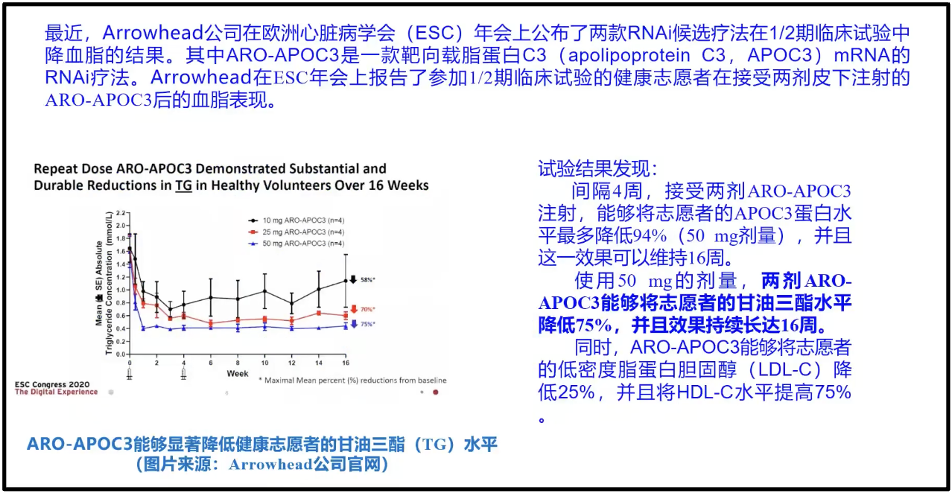
图18. RNAi 候选疗法在1/2期临床研究中的研究
所谓小 RNA 的基本原理(Segel et al. 2021; Li et al. 2014),就是小RNA进去以后会形成转录抑制复合物,所以它长期的存在,并做到所谓高效。RNA现在的药物有很多种,比如有反义核苷酸,有核酸适配体。主要的有几类,一类是小 RNA 药物, siRNA药物、circRNA 药物,一类是信使 RNA ;但是所有的实验当中获得的功能的RNA 是不能直接成为药物的。成为药物要经过两个重要阶段,一个 RNA 必须修饰,一个要找到一个好的递送系统。 RNA 修饰主要解决 四个问题,第一,要提高 RNA 的稳定性,不要进入机体里以后被降解;第二,要提高 RNA 的翻译效率;第三,要降低 RNA 本身的免疫源性;第四,要改善它跟细胞的物理化学性质的适应性。
对于递送系统,各种研究人员已经尝试了几十种不同的办法,但是在疫苗设计方面只有纳米颗粒取得较好效果(Huang et al. 2022),但是也有对其他系统进行探究,例如外泌体,张锋在 science 上发表的多态的囊包系统(Segel et al. 2021)。这些内容还都在研究,但是始终还是一个难题。
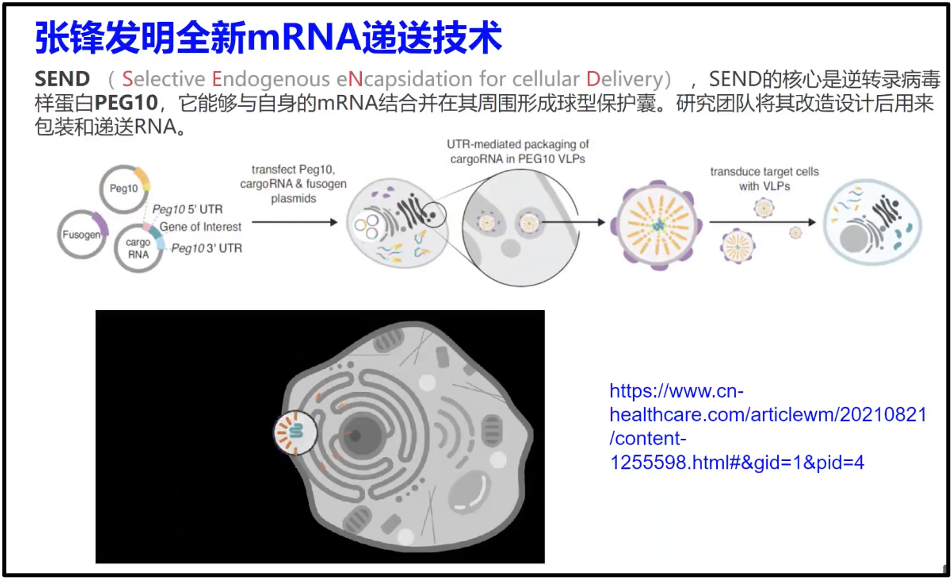
图19. mRNA 药物通过 SEND 引入到患病细胞中,实现疾病治疗
陈院士此外还举例,在2020 年调研的国际上 10 个药王中,7个是二类药物且基本上都是抗体药和分子药。如果你在 30 年前去看,大部分的药都是小分子药,但陈院士认为10 年以后在药王当中会有很多是核酸药物,是RNA药物,所以RNA很快的会进入药物的领域当中,来为人类的健康来服务。
最后陈院士总结道,我们国家在 RNA 研究上实际上是做得相当好的。在 RNA 的基础研究上,我们发表了大量的文章。陈院士曾经做过一个简单的,让第三方做个简单的统计,仅仅 2015 年到 2018 年,这四年的数据。我们中国在 RNA相关的论文的数量、总被他引的数量和 ESI 的重要文章的数量上都已经超过美国(图20)。所以我们国家在 RNA 的基础研究当中是不落后的。如果我们能够更好地把 RNA 的这些研究进行转化,应用到我们的实践当中,将会在世界上起到引领的作用。
陈院士在报告中,强调自己作为从事长期从事 RNA 研究的人,自己觉得很荣幸,也觉得有信心跟 RNA 的各位同行们一起努力,来实现我们中国 RNA 研究的突破的发展,做出中国原创性的工作。将近 30 年,我们一直在做长非编码,实际上现在还是国际上还没有开发的一个领域,我们相信在这方面我们也将会进行一些原始性的探索。
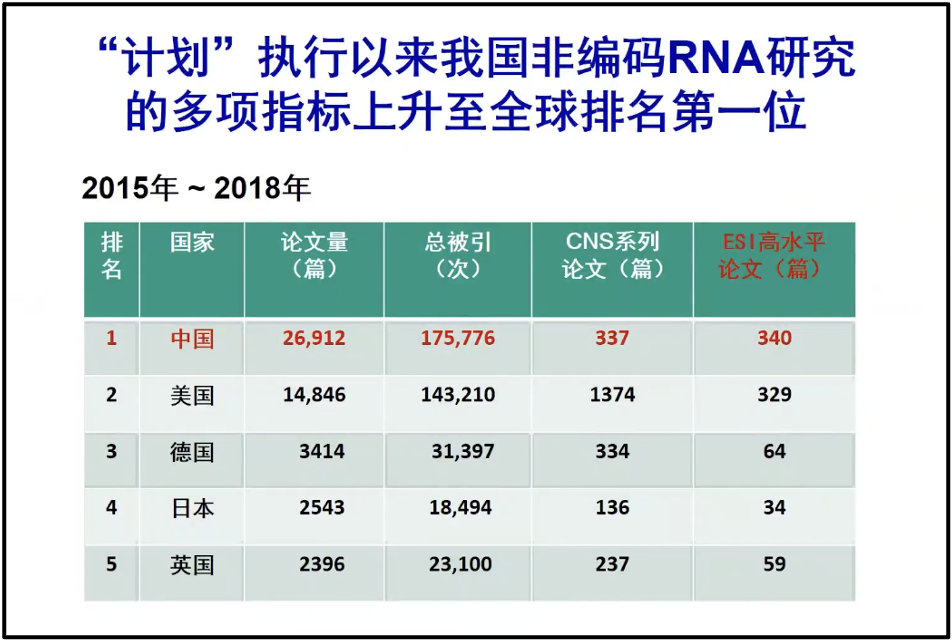
图20. 2015年-2018年各国的论文发表状况统计
精彩问答
1.非常感谢陈老师非常到位的回答,非常清楚。关于刚才陈老师报告提到的黑箱白箱的问题,本来是一个数学问题,以现在的数学手段来讲,可能还没有办法直接对其中就是黑箱里面的内在信息加以解释。如果我们在数学家彻体破译深度学习之前,或者给予深度学习里面的神经网络所有的一些,给予它直接意义之前,我们用什么额外的手段去获取黑箱中蕴含的知识。
陈院士答:这是很多人在深度学习 AI 技术当中,包括过去控制论过程讨论过的问题。实际上一步到位地把黑箱变成白箱,这很困难。基本上它是通过一套数学的方法,使得把黑箱约化,可以把它简化成若干个部分。当然我说得很简单,实际上这是一个复杂的过程,通过一块一块不断地解析,最后解决整个的黑箱问题。
对于AI 技术的网络是高度复杂的,一般来讲都有几百层,甚至多的时候可以上千层。对这样一个网络之间的结构,借助它去对生物学意义进行明确,依然是高度复杂的。所以按照控制论的办法,通过求解某个子系统过程,不断地来扩大系统,最后才使得整个黑箱变成白箱。整个过程是一个复杂的过程,可能要持续很多年,整个领域科学家的共同努力,才能不断推进这个解析的过程。
2.陈老师的报告每一次听都能有很多新的收获。今天陈老师讲到大数据与人工智能的这部分,我想到一个问题,现在借助于测序或者其他一些高通量的技术手段的发展,获取多组学数据相对于过去来要容易很多,但是现在存在问题是当我们积累了多组学数据,数据的质量它是参差不齐的。这种情况下,我们还是想要用人工智能的方法去挖掘一些内容出来。针对数据质量的这部分,我们能做一些什么,让我们的挖掘知识的过程尽量少的受到数据质量的影响。
陈院士答:你说的是非常重要非常实际的问题。实际我们 AI 的模型,人工神经网络模型是公开的,谁都可以拿到。但是如果你用一个是没有太多有“价值”知识的一个数据系统去训练它,想要构建训练网络去提取其中你认为有价值的信息,实际上很容易失败。因此一个所谓信息内涵丰富,信噪比好的这样一个数据集,对于 AI 技术能够真正帮助你挖掘信息是很重要的。所以首先数据的标准化,可能用各种各样的办法降低噪音影响,这都是在找一个好的数据集,也是在 AI 工作之前是非常重要的一步。
所以你提到的这个问题,其实现在很多人只有一个概念,首先AI是一个很好的工具。所以很多人都想拿自己有的数据去做一些尝试。实际上,很多情况下,数据的信噪比不好,很难让 AI 能够给你训练出,或者帮你挖掘出什么知识。所以AI也依赖于信噪比。不是说有了AI,你什么都可以不干了,你把什么东西都给他了,这是不对的。
所以我讲首先,非常重要的就是用户提供一个内涵丰富的、信噪比优越的、标准化的数据集。这样的数据集是使得 AI 作为一个有效工具的必然条件。所以你刚才提的问题很重要,一定要标准化,一定要降噪是,一定尽可能地让你的数据集富含更多的知识。有了这几个条件以后,再去用数据集,用 AI 的工具,才能挖掘出好的有用的知识。所以这是非常非常关键。
3.熊鹏老师是今年RNA结构预测做的最好的一个组。他问陈院士您有没有关注 RNA三维结构预测方法的进展? RNA三维结构预测方法达到什么样的精确准确度,才能帮助理解非编码RNA的功能?
陈院士答:没错,这是一个很重要的问题,我也非常关心。我们知道所谓 Alphafold 预测蛋白的结果很好, science 上也发表了类似的相应的 AI 技术来预测RNA。我始终在担心这个工具到底跟实验比精度怎么样。目前看来大家公认的是Alphafold可以跟实验相比拟了,至少在整个讨论它的结构功能的时候是可以用的。但是RNA是否到这个水平,我是持怀疑态度的。我只看到了有限的报道,没有能够让我理解,到底它的精度到什么程度。所以我自己认为 RNA 三维结构的真正的理论的预测跟实际到底有多大的距离,这个依然是值得斟酌的问题。另外一个方面,我们发现RNA 更多的,不是单独存在而是以复合物的形式存在,所以这页增加了 RNA 结构研究的复杂性。所以我觉得 RNA 的空间结构的研究还是有很多工作值得做。
4.谢谢陈老师,我主要是有两个问题。一个陈老师提到,我们在研究基因组的时候,除了蛋白编码的区域,很大的部分是非编码RNA转录的区域,还有一些有功能的,转作子的区域。但是从我个人来讲,因为我前几年很多工作是发现基因组上一些短重复序列,比如a、 t 这种重复序列,它往往在基因组上是不稳定的,容易产生损伤、突变,或者是它基本上被报道的都是有害的功能。
我就很困惑,这一部分非编码的区域,它的存在的意义和功能是什么?为什么没有在进化过程中被淘汰掉?还有第二个问题,因为我们,包括在座的老师,做了很多年的基础研究,像我现在做的也都是非常偏基础的研究。但像您提到的mRNA疫苗是个特别好的可以转化为有非常大的临床价值的一个成果。我就想听一下陈老师,对于青年科学家,怎么把基础研究的结果转化成对实际临床和应用有价值的东西,有没有什么建议?谢谢。
陈院士答:好。第一个问题是这样的,第一个问题是很重要的问题,我也在思考。比方我们现在虽然我们一直在强调我们做人类基因组 97% 的非编码的部分。国际上各种各样的数值来评估这些转录本的数量,实际上你想一想,把现在所有RNA 转录本集合,也只能覆盖现有基因组的 30% 到40%。如果我们编码的部分是3%,充其量我们现在所有得到的跟它有关的功能,跟它的转录信息表达有关的部分,也不外乎就 30%- 40%,另外还有 50%- 60%没有解决。
所以我认为,我们对基因组本身的概念实际上还很大部分,包括你刚才说的那些短的串连、重复,那些东西都包括在内。我们还有很大的可能性还没有涉及。但总的来讲,我们对整个人类基因组的解析,还需要时间,有太多的工作要做。所以我们现在,包括我自己天天在讲的 RNA 的转录部分,非编码RNA。如果把这部分作为集合删除掉,你会发现人类基因组中还有一个很大的暗区,还没有解决。
我们需要一些概念,实际上这是未来的,有些新的概念,对新的类型的理解当中的一个很重要的值得考虑的部分。总的来讲,我觉得随着生物的进化, 97% 依然没有清楚解析的部分。生物的演化是极低级的因素,当然有消极的部分,否则生物它的演化越来越高级,它就没有存在的理由。所以我相信当我们全解析了基因组,可能是几百年以后,会给我们一个答案的。这一点我觉得是没有问题的。
关于第二个问题,我自己觉得你可能在美国待过一段时间,可以理解,在西方,它的基础研究和转化是连接得比较紧密的。除了研究人员自身之内,其实学校各个相应机构都有一些保证,比方他有专门搞专利申请的,有甚至允许实验室的教授一边搞实验一边做建公司的,这就促使了它的成果能够很快地变成应用的。
所以我自己觉得目前这个形式下,一方面发现基本规律,同时也关注在你发现这些规律当中,哪些和真正的应用相关。比方跟疾病的发生发展相关,这些东西就可以以各种形式来转化。所以我觉得到底具体的怎么做,可能根据不同的情况来考虑。我们过去只强调发现科学、规律,做得更好的、更原创的工作,现在我觉得多这样一种思考也很重要。
原创的发现是否跟重要生理功能,与重要疾病的发生有关,作为一个另外的考虑,这似乎是应增加到每个 PI它自己的研究工作的日程当中来,这至少是重要的。我研究这些事情基本问题的同时也会考虑这个问题是否有用。它可以做一个药物,还是可以作为一个分子的靶标,还是可以做其他什么事?我们还可以与别人来合作去完成这个事,我觉得一边去做基础,一边你又来领导公司去完成所有的东西,这恐怕很困难。 但同时有两个思想准备,这是必要的。
陈院士此次会议报告已收录Guangzhou RNA club bilibili视频网站(https://www.bilibili.com/video/BV13D4y1W7HD/?spm_id_from=333.999.0.0&vd_source=f97b88c9400c9d0b88e6bbfbb3ff8294)
欢迎关注Guangzhou RNA club公众号、网站(rnaclub.rnacentre.org)、twitter(@RNA_club)。
Alipanahi, Babak, Andrew Delong, Matthew T. Weirauch, and Brendan J. Frey. 2015. “Predicting the Sequence Specificities of DNA- and RNA-Binding Proteins by Deep Learning.” Nature Biotechnology. https://doi.org/10.1038/nbt.3300.
Chen, R., G. I. Mias, J. Li-Pook-Than, L. Jiang, H. Y. Lam, R. Chen, E. Miriami, et al. 2012. “Personal Omics Profiling Reveals Dynamic Molecular and Medical Phenotypes.” Cell 148 (6). https://doi.org/10.1016/j.cell.2012.02.009.
Huang, Xiangang, Na Kong, Xingcai Zhang, Yihai Cao, Robert Langer, and Wei Tao. 2022. “The Landscape of mRNA Nanomedicine.” Nature Medicine 28 (11): 2273–87.
Li, Jiagen, Zhaoli Chen, Liqing Tian, Chengcheng Zhou, Max Yifan He, Yibo Gao, Suya Wang, et al. 2014. “LncRNA Profile Study Reveals a Three-lncRNA Signature Associated with the Survival of Patients with Oesophageal Squamous Cell Carcinoma.” Gut 63 (11): 1700–1710.
Liu, Benyu, Buqing Ye, Liuliu Yang, Xiaoxiao Zhu, Guanling Huang, Pingping Zhu, Ying Du, et al. 2017. “Long Noncoding RNA lncKdm2b Is Required for ILC3 Maintenance by Initiation of Zfp292 Expression.” Nature Immunology 18 (5): 499–508.
Segel, Michael, Blake Lash, Jingwei Song, Alim Ladha, Catherine C. Liu, Xin Jin, Sergei L. Mekhedov, Rhiannon K. Macrae, Eugene V. Koonin, and Feng Zhang. 2021. “Mammalian Retrovirus-like Protein PEG10 Packages Its Own mRNA and Can Be Pseudotyped for mRNA Delivery.” Science 373 (6557): 882–89.
Snyder, Michael. 2014. “Personalized Medicine: Personal Omics Profiling of Healthy and Disease States (475.1).” The FASEB Journal. https://doi.org/10.1096/fasebj.28.1_supplement.475.1.
Wang, Yanying, Lei He, Ying Du, Pingping Zhu, Guanling Huang, Jianjun Luo, Xinlong Yan, et al. 2015. “The Long Noncoding RNA lncTCF7 Promotes Self-Renewal of Human Liver Cancer Stem Cells through Activation of Wnt Signaling.” Cell Stem Cell. https://doi.org/10.1016/j.stem.2015.03.003.
 Guangzhou RNA club
Guangzhou RNA club